Rethinking Your Knowledge Base Architecture: Why Bite-Size is Best
Se você está dependendo do Control-F para pesquisar em documentos de várias páginas em seu repositório de conhecimento corporativo, é hora de repensar toda a sua arquitetura de conhecimento — e mover-se em direção a peças de conhecimento curtas, facilmente consumíveis e discretas.
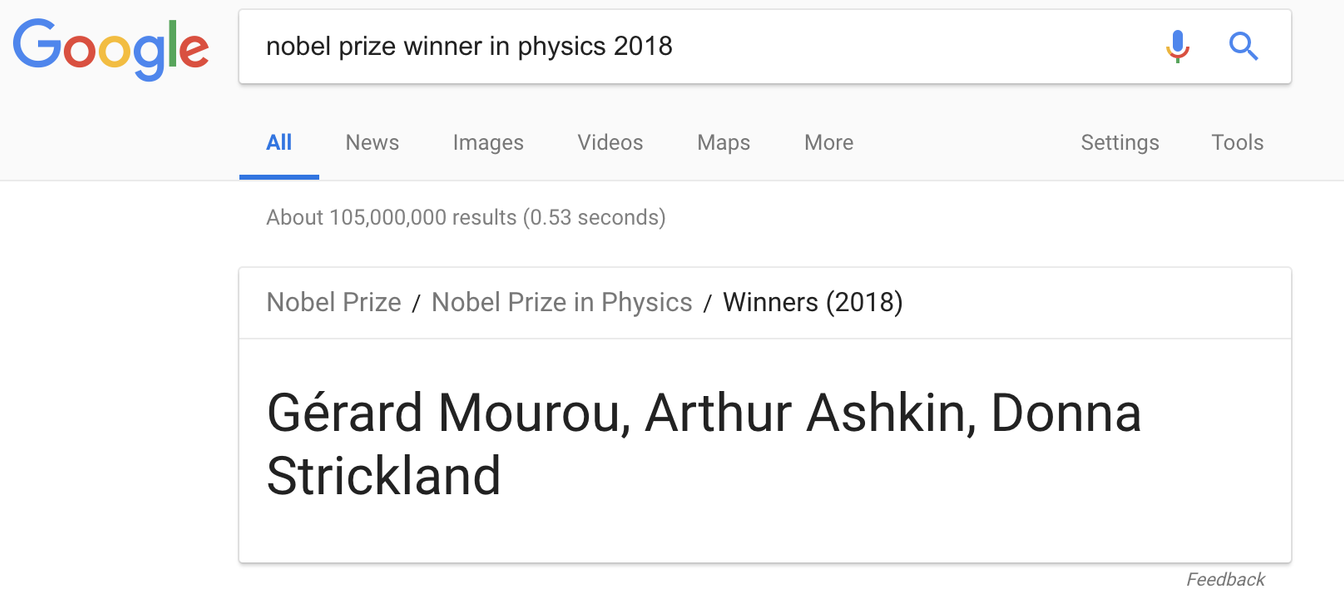
Quando o Google introduziu seu Knowledge Graph nas páginas de resultados do mecanismo de busca (SERPs) em 2012, seus snippets em destaque (aqueles pontos de dados curtos e relevantes que ficam no topo da página) tornaram-se a solução preferida para quem precisa de uma resposta rápida. Fortemente dependente de dados extraídos de sites como a Wikipedia, o Google foi capaz de utilizar dados compilados por outros para mantê-lo em seu ecossistema — um benefício para um fluxo de receita acionado por publicidade. Mas algo mais também aconteceu: o tráfego para a Wikipedia caiu. Embora qualquer estatístico tenha o direito de nos lembrar que correlação não é igual a ou implica em causalidade, também podemos olhar para nosso próprio comportamento para entender o que aconteceu. Se tudo o que você precisa saber é, digamos, quem ganhou o Prêmio Nobel de Física este ano e a resposta está no topo da página, não há necessidade de continuar procurando nas outras 105 milhões de resultados.
Sabemos isso instintivamente, mas quando se trata de nossos portais de conhecimento, muitas vezes estamos configurando-os para atuar como repositórios, e não como uma forma fácil de encontrar informações de que precisamos. É por isso que — e isso pode ser difícil de ouvir — precisamos repensar completamente nossa abordagem.
Se o seu portal de conhecimento corporativo é como a maioria, quando você tem uma pergunta, você tem que saber a) exatamente o que está procurando ou b) você tem que pesquisar por centenas (ou milhares!) de palavras em FAQs ou PDFs de várias páginas para encontrar uma resposta que está enterrada em algum lugar deles.
O Control-F tem sido fundamental para fazer essa configuração funcionar, mas por que você deve ter que usar o que é efetivamente uma solução alternativa só para obter uma resposta simples? Não só coloca o ônus no empregado para descobrir o conhecimento (o que pode levar um tempo não insignificante), mas também significa que, sempre que qualquer um desse conhecimento muda, a empresa tem que fazer o upload de um novo PDF, vídeo ou FAQ completamente novo. Isso desperdiça tempo — e orçamentos.
A melhor solução é repensar completamente sua arquitetura de conhecimento e mover-se em direção a peças de conhecimento curtas, facilmente consumíveis (e atualizáveis).
Busca e resgate
“Olha, não é tão ruim assim,” você provavelmente está dizendo agora, “dá conta do recado!” Então vamos falar sobre isso. Esta não é a primeira vez que falamos sobre isso no blog do Guru. Quase três anos atrás, apontamos que:
Os vendedores passam até um terço de seus dias procurando informações necessárias para fazer seus trabalhos. Informações são necessárias sob demanda, e as soluções atuais não foram feitas para um mundo sob demanda. Docs e wikis forçam você a usar Control+F para encontrar palavras e depois deixar você montar as respostas.
Se você está conversando com um cliente e precisa responder a uma pergunta, você não tem tempo para passar pelo longo e ineficiente processo atual para encontrar a resposta. Pesquisar o documento que terá a resposta correta, abrir esse documento, pesquisar uma palavra-chave e, após tudo isso, em vez de sua resposta aparecer, você vê que a palavra digitada aparece quinze vezes. Para obter a informação adequada, você tem que clicar em todas as opções, enquanto isso o seu cliente está esperando por sua resposta.
Mas vai além de apenas desperdiçar valiosos segundos. Conteúdos mais longos são apenas mais difíceis de pesquisar do que conteúdos mais curtos. Vamos tirar isso da esfera da gestão do conhecimento e levá-lo a uma que todos podemos nos identificar: como nos envolvemos com conteúdos para fins de lazer.
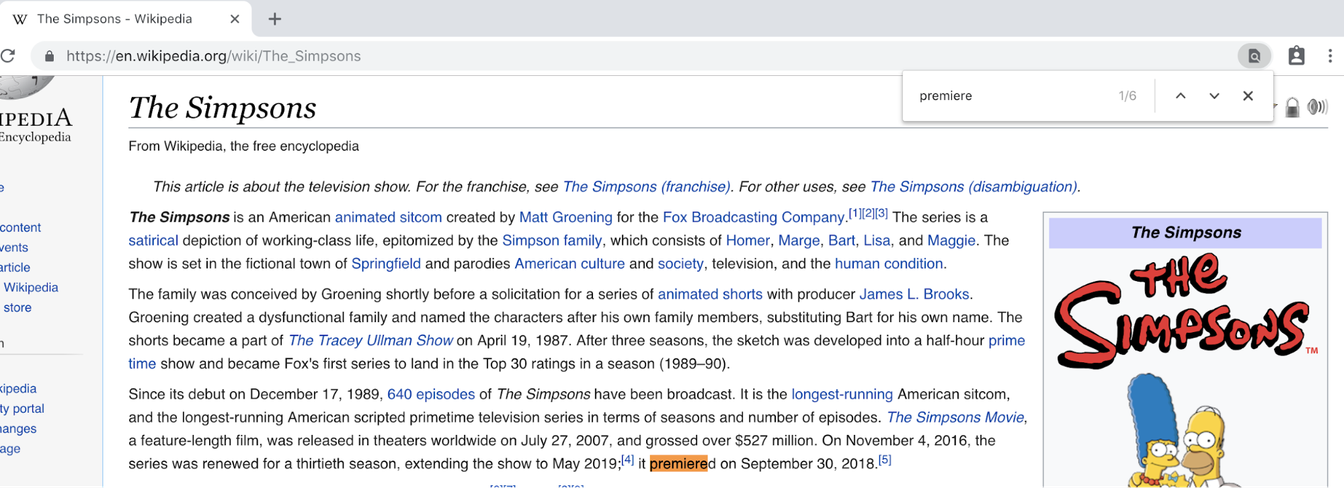
Aqui está uma pergunta que você pode ou não saber a resposta: Em que ano Os Simpsons estreou? Você acessa a Wikipedia, pesquisa “Os Simpsons” e obtém esta página com mais de 17.000 palavras. Você confia no seu velho conhecido Control-F e pesquisa “estreia” e acontece isso:
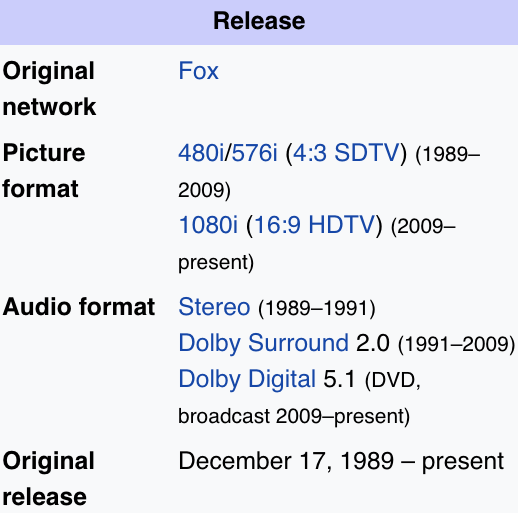
Espera, o que? Acontece que você precisava pesquisar “lançamento”:
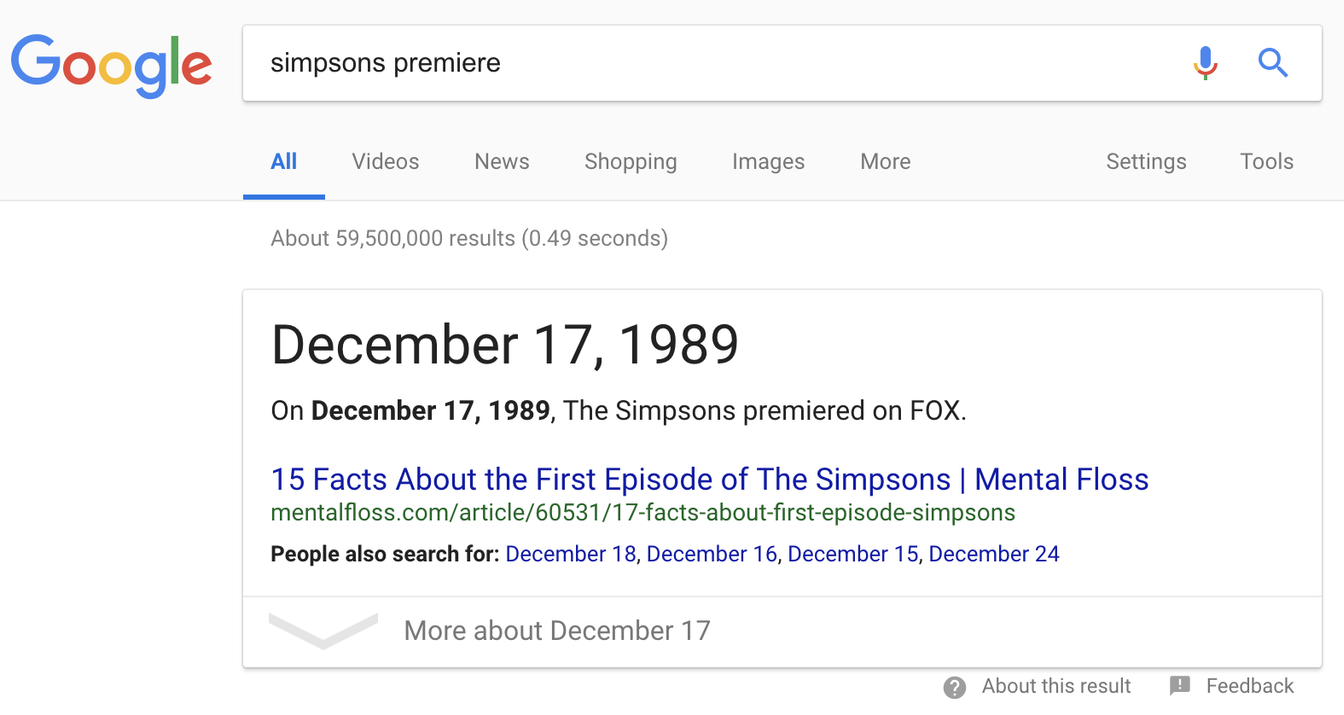
Não só você precisava saber exatamente como esta página (altamente organizada, devemos ressaltar) está configurada, você precisa saber exatamente a terminologia que os escritores usaram para indicar uma data de início. Enquanto isso, se você for ao Google e apenas digitar “estreia dos Simpsons”, você obtém isso:
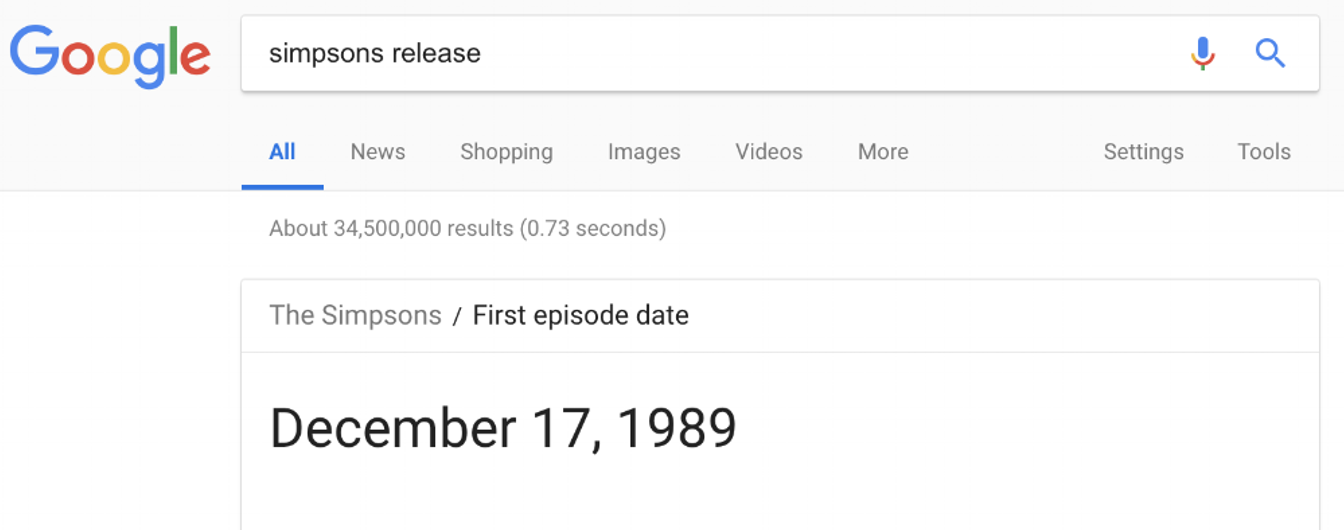
Pesquise por “lançamento dos Simpsons” e você obtém a mesma informação, embora apresentada de forma um pouco diferente:
De qualquer forma, o resultado é útil, rápido e, o mais importante, fácil de encontrar, independentemente da redação exata que você usou. Você nem precisou usar o Control-F.
Eu ainda não encontrei o que estou procurando
Agora, vamos levar essa discussão de volta para a gestão do conhecimento. Seus PDFs espaçados ajustados, fonte de 10pt, de três páginas e FAQs de 48 itens são ótimos — para economizar nos custos de impressão. Eles não são bons para focar facilmente exatamente no que seus funcionários precisam saber, seja sobre informações de benefícios na integração, documentação do produto em um lançamento ou mesmo tentando encontrar o folheto correto para distribuir.
Engraçado, quanto mais do nosso conhecimento digitalizamos, mais temos que depender de soluções alternativas para realmente focar no que precisamos encontrar. Aqueles livros didáticos tão mal vistos da sua juventude? O índice era a parte com a qual você passava mais tempo de qualidade. Depois de tudo, ele lhe dizia exatamente onde encontrar o que precisava — e ignorar o que não precisava — e geralmente incluía quebras contextuais também (ex: A Missão à Lua, reação da URSS a).
Agora? Estamos fazendo um trabalho que computadores e IA podem fazer de forma mais eficiente, se apenas os deixarmos. Armazenar seu conhecimento em pedaços pequenos significa que qualquer busca contextual pode ocorrer muito, muito mais rapidamente. Muitas empresas falam sobre suas capacidades de aprendizado de máquina e IA na busca empresarial — mas todas essas soluções são inúteis se tudo o que conseguem fazer é trazer um documento de 30 páginas que seus funcionários ainda têm que pesquisar.
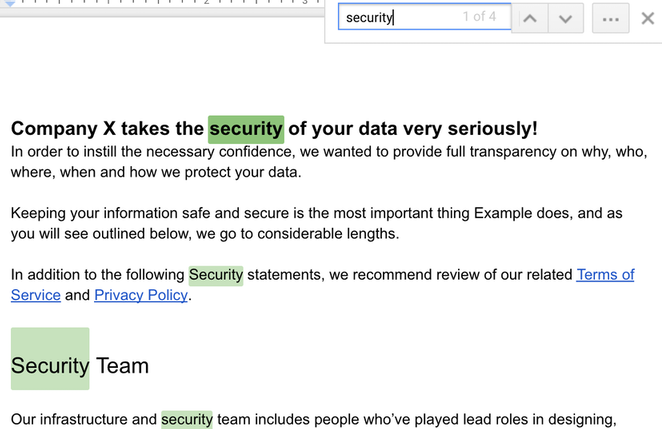
Se os documentos não foram feitos para serem impressos, não há razão para não dividi-los em componentes individuais para proporcionar uma melhor experiência de referência de conhecimento. Caso contrário, como empresa, você pode estar pagando seus funcionários para fazer o trabalho manual de procurar por 50 instâncias destacadas da palavra “segurança” em um documento de produto — e eles ainda podem não encontrar o que estão procurando, porque não podem dar mais contexto a uma pesquisa de Control-F.
Essa abordagem não beneficia apenas aqueles que adicionam e mantêm conhecimento; também é uma grande ajuda para sua equipe de receita. Quando um vendedor está tentando fechar um negócio, você prefere que ela tenha acesso instantâneo a informações específicas ou... executar um comando de busca em um documento de prontidão de vendas com 45 itens? Se seu representante de suporte ao cliente está recebendo uma ligação de um cliente irritado, você quer que ele fique revistando freneticamente uma FAQ à procura de uma resposta ou empoderá-lo para acessar apenas a seção relevante?
Construindo uma base de conhecimento sustentável
Vimos que cartões de conhecimento em pedaços pequenos funcionam para nós, razão pela qual sabemos que eles também podem funcionar para você. Não só torna mais rápido e fácil encontrar as informações de que realmente precisa, como também significa que a manutenção do conhecimento é muito mais simples. Saiba mais sobre os benefícios de adotar um sistema de gestão de conhecimento em toda a empresa.
Ao implementar uma abordagem em formato curto para a arquitetura da base de conhecimento, você se livra da necessidade constante de fazer upload de toda a nova documentação. Uma atualização de uma frase em um documento de 20 páginas significa que você tem que fazer o upload de todo o documento novamente e garantir que todos estejam cientes da mudança, porque está enterrada no nono ponto em lista na página 12.
Alternativamente, uma atualização de uma frase em um pedaço de conhecimento com quatro frases pode acontecer em questão de segundos. Essa abordagem também torna muito mais fácil verificar informações em pedaços pequenos para garantir sua precisão do que verificar documentos mais longos, já que cada peça de conhecimento pode ser individualmente verificada como correta — e a verificação é, em última análise, o núcleo da criação de uma rede de conhecimento em que todos possam confiar.
Claro, sabemos que, ironicamente, isso é muita palavra para explicar por que conteúdos curtos são uma abordagem melhor para a arquitetura do conhecimento, então aqui está o resumindo: conteúdos em pedaços pequenos são mais fáceis de adicionar, mais fáceis de atualizar, mais fáceis de verificar e mais fáceis de pesquisar. Pense nisso como cartões de vocabulário vs. o dicionário: um tem tudo, mas não vai ajudá-lo a se preparar para o teste da semana que vem, enquanto o outro é exatamente o que você precisa para passar no teste, pode ser ampliado para ajudá-lo a passar pela prova de meio de semestre e final, e é flexível o suficiente para ser reorganizado de um milhão de maneiras diferentes. Qual você escolheria?
Quando o Google introduziu seu Knowledge Graph nas páginas de resultados do mecanismo de busca (SERPs) em 2012, seus snippets em destaque (aqueles pontos de dados curtos e relevantes que ficam no topo da página) tornaram-se a solução preferida para quem precisa de uma resposta rápida. Fortemente dependente de dados extraídos de sites como a Wikipedia, o Google foi capaz de utilizar dados compilados por outros para mantê-lo em seu ecossistema — um benefício para um fluxo de receita acionado por publicidade. Mas algo mais também aconteceu: o tráfego para a Wikipedia caiu. Embora qualquer estatístico tenha o direito de nos lembrar que correlação não é igual a ou implica em causalidade, também podemos olhar para nosso próprio comportamento para entender o que aconteceu. Se tudo o que você precisa saber é, digamos, quem ganhou o Prêmio Nobel de Física este ano e a resposta está no topo da página, não há necessidade de continuar procurando nas outras 105 milhões de resultados.
Sabemos isso instintivamente, mas quando se trata de nossos portais de conhecimento, muitas vezes estamos configurando-os para atuar como repositórios, e não como uma forma fácil de encontrar informações de que precisamos. É por isso que — e isso pode ser difícil de ouvir — precisamos repensar completamente nossa abordagem.
Se o seu portal de conhecimento corporativo é como a maioria, quando você tem uma pergunta, você tem que saber a) exatamente o que está procurando ou b) você tem que pesquisar por centenas (ou milhares!) de palavras em FAQs ou PDFs de várias páginas para encontrar uma resposta que está enterrada em algum lugar deles.
O Control-F tem sido fundamental para fazer essa configuração funcionar, mas por que você deve ter que usar o que é efetivamente uma solução alternativa só para obter uma resposta simples? Não só coloca o ônus no empregado para descobrir o conhecimento (o que pode levar um tempo não insignificante), mas também significa que, sempre que qualquer um desse conhecimento muda, a empresa tem que fazer o upload de um novo PDF, vídeo ou FAQ completamente novo. Isso desperdiça tempo — e orçamentos.
A melhor solução é repensar completamente sua arquitetura de conhecimento e mover-se em direção a peças de conhecimento curtas, facilmente consumíveis (e atualizáveis).
Busca e resgate
“Olha, não é tão ruim assim,” você provavelmente está dizendo agora, “dá conta do recado!” Então vamos falar sobre isso. Esta não é a primeira vez que falamos sobre isso no blog do Guru. Quase três anos atrás, apontamos que:
Os vendedores passam até um terço de seus dias procurando informações necessárias para fazer seus trabalhos. Informações são necessárias sob demanda, e as soluções atuais não foram feitas para um mundo sob demanda. Docs e wikis forçam você a usar Control+F para encontrar palavras e depois deixar você montar as respostas.
Se você está conversando com um cliente e precisa responder a uma pergunta, você não tem tempo para passar pelo longo e ineficiente processo atual para encontrar a resposta. Pesquisar o documento que terá a resposta correta, abrir esse documento, pesquisar uma palavra-chave e, após tudo isso, em vez de sua resposta aparecer, você vê que a palavra digitada aparece quinze vezes. Para obter a informação adequada, você tem que clicar em todas as opções, enquanto isso o seu cliente está esperando por sua resposta.
Mas vai além de apenas desperdiçar valiosos segundos. Conteúdos mais longos são apenas mais difíceis de pesquisar do que conteúdos mais curtos. Vamos tirar isso da esfera da gestão do conhecimento e levá-lo a uma que todos podemos nos identificar: como nos envolvemos com conteúdos para fins de lazer.
Aqui está uma pergunta que você pode ou não saber a resposta: Em que ano Os Simpsons estreou? Você acessa a Wikipedia, pesquisa “Os Simpsons” e obtém esta página com mais de 17.000 palavras. Você confia no seu velho conhecido Control-F e pesquisa “estreia” e acontece isso:
Espera, o que? Acontece que você precisava pesquisar “lançamento”:
Não só você precisava saber exatamente como esta página (altamente organizada, devemos ressaltar) está configurada, você precisa saber exatamente a terminologia que os escritores usaram para indicar uma data de início. Enquanto isso, se você for ao Google e apenas digitar “estreia dos Simpsons”, você obtém isso:
Pesquise por “lançamento dos Simpsons” e você obtém a mesma informação, embora apresentada de forma um pouco diferente:
De qualquer forma, o resultado é útil, rápido e, o mais importante, fácil de encontrar, independentemente da redação exata que você usou. Você nem precisou usar o Control-F.
Eu ainda não encontrei o que estou procurando
Agora, vamos levar essa discussão de volta para a gestão do conhecimento. Seus PDFs espaçados ajustados, fonte de 10pt, de três páginas e FAQs de 48 itens são ótimos — para economizar nos custos de impressão. Eles não são bons para focar facilmente exatamente no que seus funcionários precisam saber, seja sobre informações de benefícios na integração, documentação do produto em um lançamento ou mesmo tentando encontrar o folheto correto para distribuir.
Engraçado, quanto mais do nosso conhecimento digitalizamos, mais temos que depender de soluções alternativas para realmente focar no que precisamos encontrar. Aqueles livros didáticos tão mal vistos da sua juventude? O índice era a parte com a qual você passava mais tempo de qualidade. Depois de tudo, ele lhe dizia exatamente onde encontrar o que precisava — e ignorar o que não precisava — e geralmente incluía quebras contextuais também (ex: A Missão à Lua, reação da URSS a).
Agora? Estamos fazendo um trabalho que computadores e IA podem fazer de forma mais eficiente, se apenas os deixarmos. Armazenar seu conhecimento em pedaços pequenos significa que qualquer busca contextual pode ocorrer muito, muito mais rapidamente. Muitas empresas falam sobre suas capacidades de aprendizado de máquina e IA na busca empresarial — mas todas essas soluções são inúteis se tudo o que conseguem fazer é trazer um documento de 30 páginas que seus funcionários ainda têm que pesquisar.
Se os documentos não foram feitos para serem impressos, não há razão para não dividi-los em componentes individuais para proporcionar uma melhor experiência de referência de conhecimento. Caso contrário, como empresa, você pode estar pagando seus funcionários para fazer o trabalho manual de procurar por 50 instâncias destacadas da palavra “segurança” em um documento de produto — e eles ainda podem não encontrar o que estão procurando, porque não podem dar mais contexto a uma pesquisa de Control-F.
Essa abordagem não beneficia apenas aqueles que adicionam e mantêm conhecimento; também é uma grande ajuda para sua equipe de receita. Quando um vendedor está tentando fechar um negócio, você prefere que ela tenha acesso instantâneo a informações específicas ou... executar um comando de busca em um documento de prontidão de vendas com 45 itens? Se seu representante de suporte ao cliente está recebendo uma ligação de um cliente irritado, você quer que ele fique revistando freneticamente uma FAQ à procura de uma resposta ou empoderá-lo para acessar apenas a seção relevante?
Construindo uma base de conhecimento sustentável
Vimos que cartões de conhecimento em pedaços pequenos funcionam para nós, razão pela qual sabemos que eles também podem funcionar para você. Não só torna mais rápido e fácil encontrar as informações de que realmente precisa, como também significa que a manutenção do conhecimento é muito mais simples. Saiba mais sobre os benefícios de adotar um sistema de gestão de conhecimento em toda a empresa.
Ao implementar uma abordagem em formato curto para a arquitetura da base de conhecimento, você se livra da necessidade constante de fazer upload de toda a nova documentação. Uma atualização de uma frase em um documento de 20 páginas significa que você tem que fazer o upload de todo o documento novamente e garantir que todos estejam cientes da mudança, porque está enterrada no nono ponto em lista na página 12.
Alternativamente, uma atualização de uma frase em um pedaço de conhecimento com quatro frases pode acontecer em questão de segundos. Essa abordagem também torna muito mais fácil verificar informações em pedaços pequenos para garantir sua precisão do que verificar documentos mais longos, já que cada peça de conhecimento pode ser individualmente verificada como correta — e a verificação é, em última análise, o núcleo da criação de uma rede de conhecimento em que todos possam confiar.
Claro, sabemos que, ironicamente, isso é muita palavra para explicar por que conteúdos curtos são uma abordagem melhor para a arquitetura do conhecimento, então aqui está o resumindo: conteúdos em pedaços pequenos são mais fáceis de adicionar, mais fáceis de atualizar, mais fáceis de verificar e mais fáceis de pesquisar. Pense nisso como cartões de vocabulário vs. o dicionário: um tem tudo, mas não vai ajudá-lo a se preparar para o teste da semana que vem, enquanto o outro é exatamente o que você precisa para passar no teste, pode ser ampliado para ajudá-lo a passar pela prova de meio de semestre e final, e é flexível o suficiente para ser reorganizado de um milhão de maneiras diferentes. Qual você escolheria?
Quer aprender como o Guru pode funcionar para você e sua equipe?