Rethinking Your Knowledge Base Architecture: Why Bite-Size is Best
Si vous comptez sur Control-F pour rechercher dans des documents multi-pages dans votre référentiel de connaissances d'entreprise, il est temps de repenser complètement votre architecture de connaissances — et de vous orienter vers des morceaux de connaissances courts, facilement consommables et discrets.
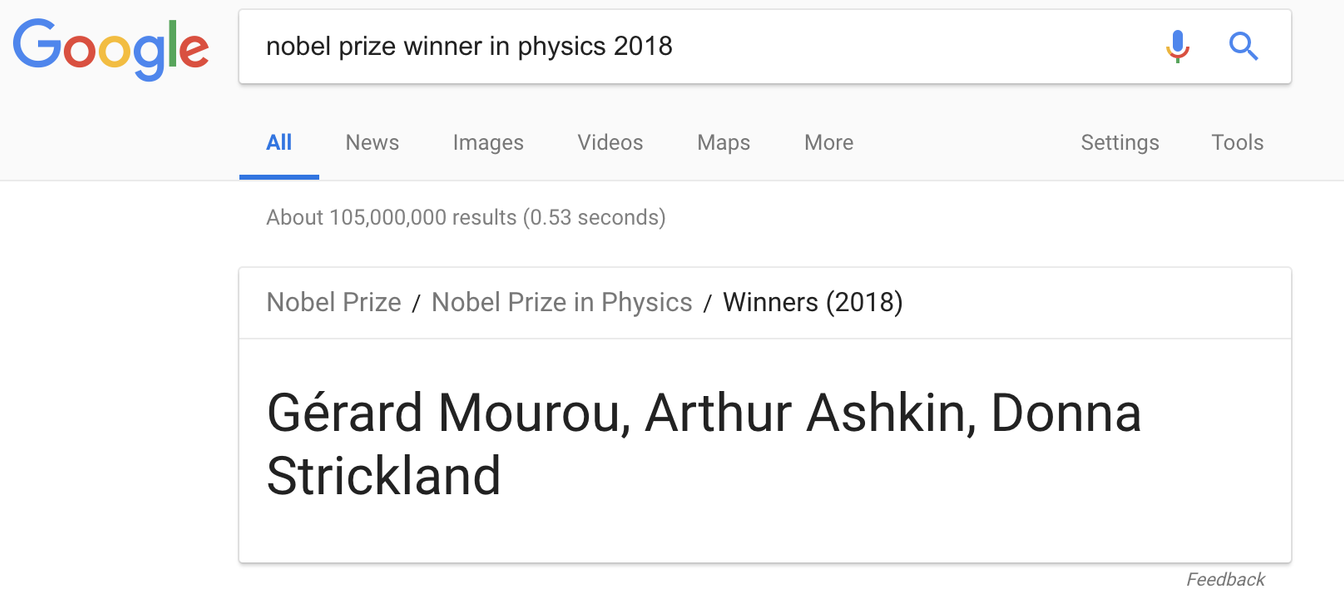
Lorsque Google a introduit son Knowledge Graph sur les pages de résultats des moteurs de recherche (SERPs) en 2012, ses extraits mis en avant (ces courts points de données pertinents qui vivent en haut de la page) sont devenus la référence pour ceux qui avaient besoin d'une réponse rapide. Énormément dépendant du scraping de données provenant de sites comme Wikipedia, Google a pu tirer parti des données compilées par d'autres pour vous garder dans son écosystème — un avantage pour un modèle de revenus basé sur la publicité. Mais autre chose est aussi arrivée : le trafic vers Wikipedia a diminué. Bien qu'un statisticien ait le droit de nous rappeler que la corrélation n'implique pas la causalité, nous pouvons également observer notre propre comportement pour avoir une idée de ce qui s'est passé. Si tout ce que vous devez savoir est, disons, qui a gagné le Prix Nobel de Physique cette année et que la réponse se trouve en haut de la page, il n'est pas nécessaire de continuer à chercher parmi les autres 105 millions de résultats.
Nous le savons instinctivement, mais en ce qui concerne nos portails de connaissances, nous avons souvent tendance à les configurer pour qu'ils agissent comme des dépôts, et non comme un moyen de faire émerger facilement les informations dont nous avons besoin. C'est pourquoi — et cela peut être difficile à entendre — nous devons complètement repenser notre approche.
Si votre portail de connaissances d'entreprise est comme la plupart, lorsque vous avez une question, vous devez savoir a) exactement ce que vous cherchez ou b) vous devez parcourir des centaines (ou des milliers !) de mots dans des FAQ multi-pages ou des PDF pour trouver une réponse qui est enfouie quelque part.
Control-F a été essentiel pour faire fonctionner cette configuration, mais pourquoi devriez-vous utiliser ce qui est en fin de compte un contournement juste pour obtenir une réponse simple ? Non seulement cela impose le fardeau à l'employé de déterrer les connaissances (ce qui peut prendre beaucoup de temps), mais cela signifie que chaque fois que l'une de ces connaissances change, l'entreprise doit télécharger un tout nouveau PDF, vidéo ou FAQ. Cela fait perdre du temps — et des budgets.
La meilleure solution consiste à repenser entièrement votre architecture de connaissances et à se tourner vers des morceaux de connaissances courts, faciles à consommer (et à mettre à jour), discrets.
Recherche et sauvetage
« Regarde, ce n'est pas si mauvais », vous dites probablement en ce moment, « ça fait le travail ! » Alors parlons de cela. Ce n'est même pas la première fois que nous avons parlé de cela sur le blog de Guru. Il y a presque trois ans, nous avons souligné que :
Les commerciaux passent jusqu'à un tiers de leur journée à chercher des informations nécessaires pour faire leur travail. Les informations sont nécessaires à la demande, et les solutions actuelles ne sont pas adaptées à un monde à la demande. Les docs et wikis vous obligent à utiliser Control+F pour trouver des mots, puis vous laissent reconstituer les réponses.
Si vous discutez avec un client et devez répondre à une question, vous n'avez pas le temps de passer par le long et inefficace processus actuel pour trouver la réponse. Rechercher le document qui aura la bonne réponse, ouvrir ce document, chercher un mot-clé, et après tout ça au lieu que votre réponse apparaisse, vous voyez que le mot que vous avez tapé apparaît quinze fois. Pour obtenir l'information appropriée, vous devez parcourir toutes les options, pendant ce temps votre client attend sa réponse.
Mais cela va au-delà de la simple perte de précieuses secondes. Du contenu plus long est tout simplement plus difficile à rechercher que du contenu plus court. Sortons cela du domaine de la gestion des connaissances et mettons-le dans un domaine qui nous concerne tous : comment nous engageons avec le contenu à des fins de loisirs.
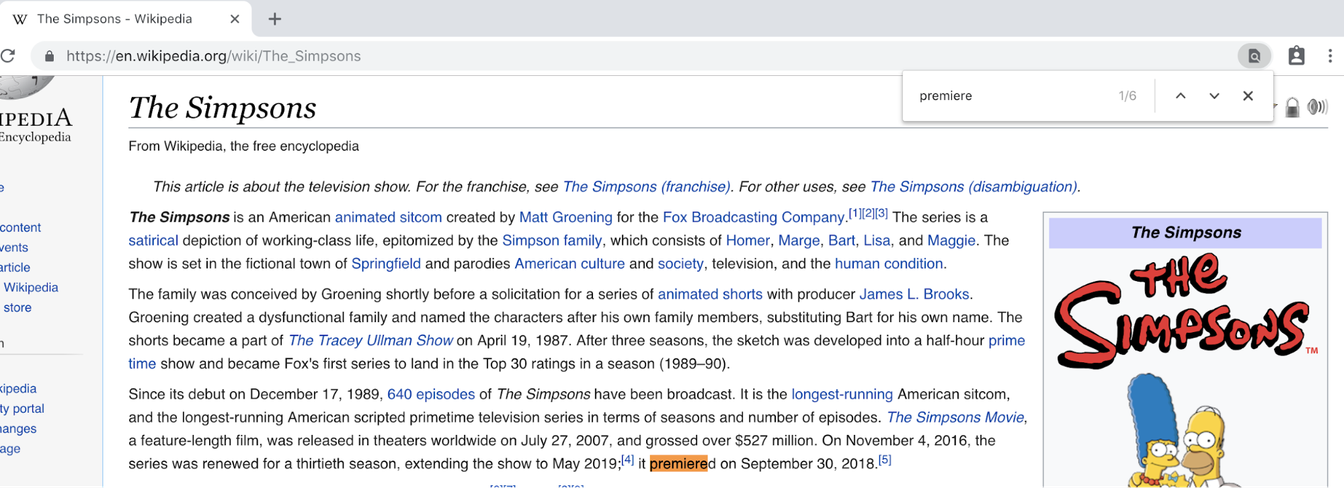
Voici une question à laquelle vous ne savez peut-être pas répondre : Quelle année Les Simpsons a-t-il été diffusé pour la première fois ? Vous consultez Wikipedia, entrez « Les Simpsons » et obtenez cette page avec plus de 17 000 mots. Vous comptez sur votre fidèle Control-F et recherchez « première » et voilà ce qui arrive :
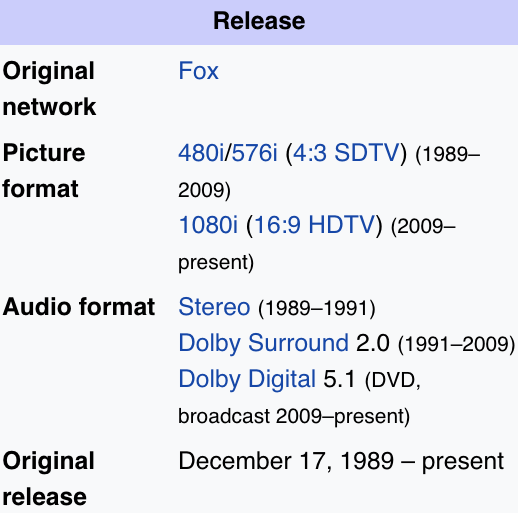
Attendez, quoi? Il s'avère que vous deviez rechercher « sortie » :
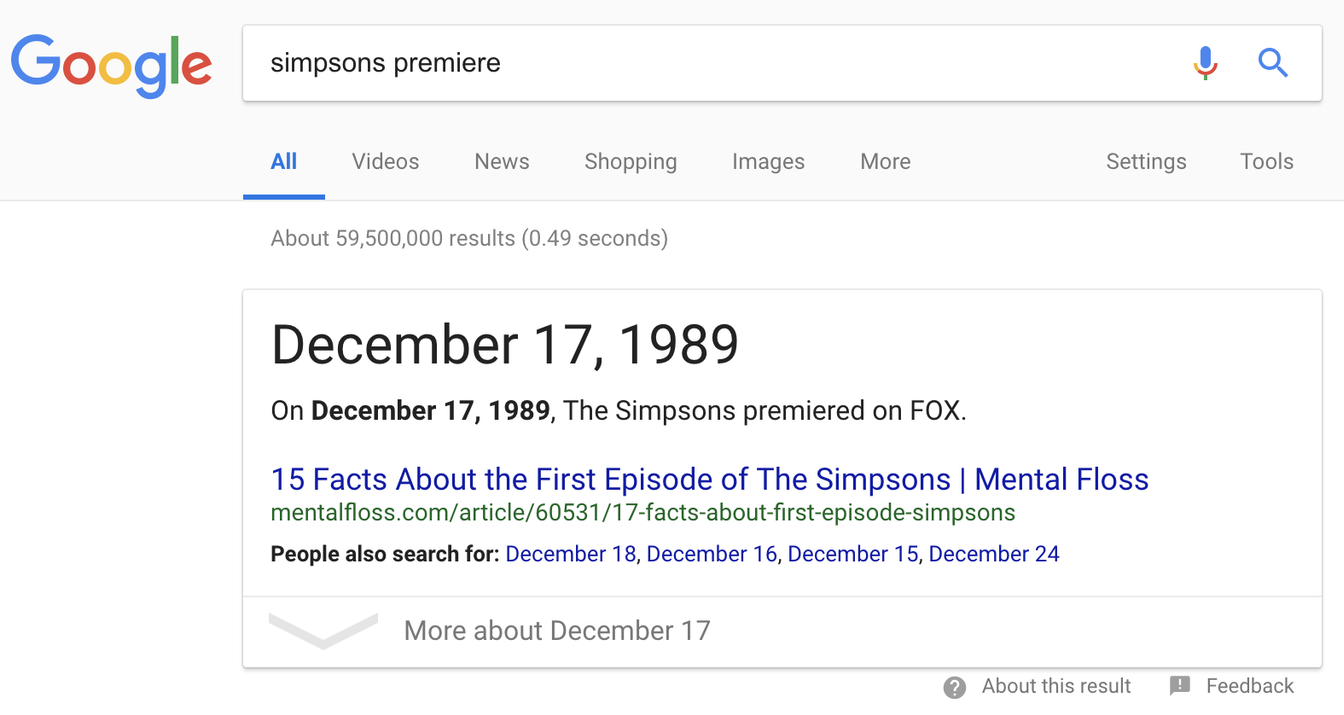
Non seulement vous deviez savoir exactement comment cette page (hautement organisée, devons-nous le souligner) est configurée, mais vous deviez également connaître exactement la terminologie utilisée par les rédacteurs pour indiquer une date de début. Pendant ce temps, si vous allez sur Google et tapez simplement « première des Simpsons », vous obtenez ceci :
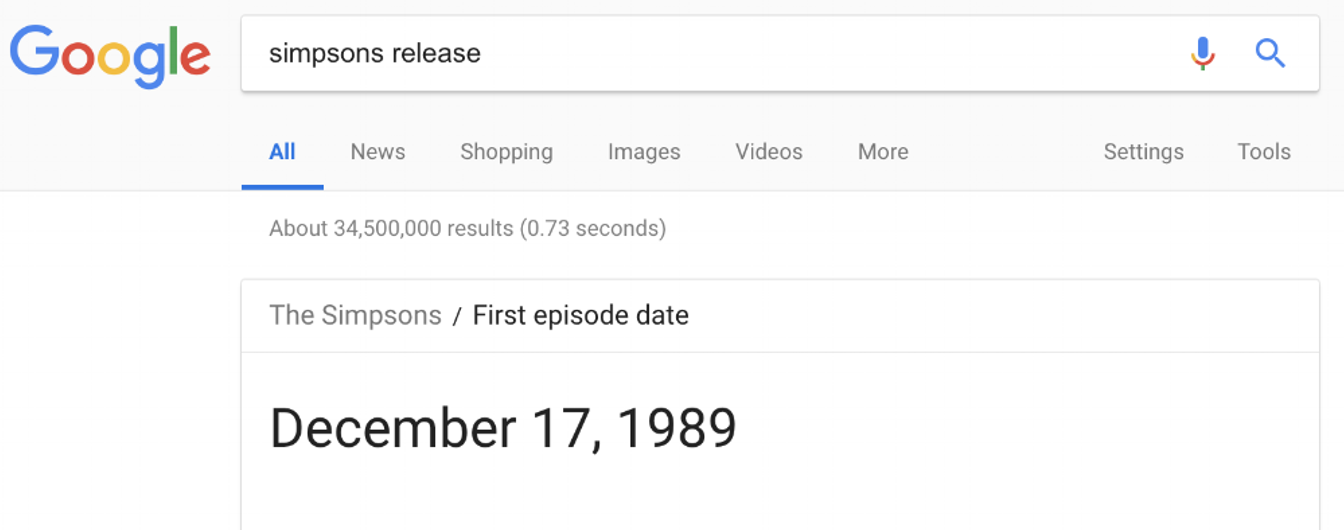
Recherchez « sortie des Simpsons » et vous obtenez les mêmes informations, même si elles sont présentées un peu différemment :
De toute façon, le résultat est utile, rapide et, surtout, facile à trouver indépendamment du mot exact que vous avez utilisé. Vous n'avez même pas eu besoin d'utiliser Control-F.
Je n'ai même pas trouvé ce que je cherche
Maintenant, revenons à cette discussion sur la gestion des connaissances. Vos PDF serrés, en police de 10pt, de trois pages et vos FAQ de 48 articles sont super — pour économiser sur les coûts d'impression. Ils ne sont pas idéaux pour se concentrer facilement sur ce que vos employés doivent savoir, que ce soit des informations sur les avantages lors de l'intégration, de la documentation produit lors d'un lancement, ou même essayer de trouver le bon document à distribuer.
C'est drôle, plus nous avons numérisé nos connaissances, plus nous avons dû compter sur des solutions de contournement pour arriver à ce que nous devions trouver. Ces manuels tant détestés de votre jeunesse ? L'index était la partie avec laquelle vous avez passé le plus de temps de qualité. Après tout, il vous indiquait exactement où trouver ce dont vous aviez besoin — et ce qu'il fallait ignorer — et comprenait généralement aussi des explications contextuelles (ex : le débarquement sur la Lune, la réaction de l'URSS).
Maintenant ? Nous nous forcions à faire un travail que les ordinateurs et l'IA peuvent faire plus efficacement, si nous les laissons faire. Stocker votre connaissance en morceaux de petite taille signifie que toute recherche contextuelle peut se faire beaucoup plus rapidement. Beaucoup d'entreprises parlent de leurs capacités d'apprentissage automatique et d'IA dans la recherche d'entreprise — mais toutes ces solutions sont inutiles si tout ce qu'elles peuvent faire est de fournir un document de 30 pages que vos employés doivent continuer à chercher.
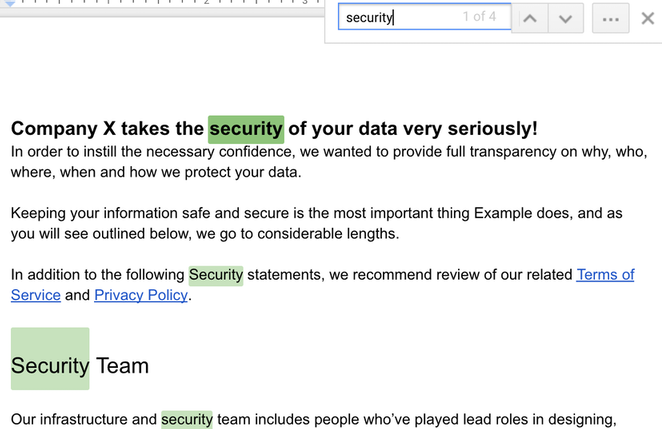
Si les documents ne sont pas destinés à être imprimés, il n'y a aucune raison de ne pas les diviser en composants individuels pour améliorer l'expérience de référence des connaissances. Sinon, en tant qu'entreprise, vous pourriez payer vos employés pour effectuer le travail manuel de recherche à travers 50 instances surlignées du mot "sécurité" dans un document produit — et ils pourraient encore ne pas trouver ce qu'ils cherchent, car ils ne peuvent pas ajouter plus de contexte à une recherche Control-F.
Cette approche ne bénéficie pas seulement à ceux qui ajoutent et maintiennent les connaissances ; c'est également un énorme coup de pouce pour votre équipe de revenus. Lorsqu'un commercial essaie de conclure un accord, préférez-vous qu'elle ait un accès instantané à des informations spécifiques ou... qu'elle exécute une commande de recherche sur un document de préparation à la vente de 45 points ? Si votre agent de support client est à l'autre bout d'un appel téléphonique en colère, voulez-vous qu'il feuillette furieusement une FAQ pour trouver une réponse, ou l'habiliter à extraire juste la section pertinente ?
Construire une fondation de connaissances durable
Nous avons vu que les cartes de connaissances de petite taille fonctionnent pour nous, c'est pourquoi nous savons qu'elles peuvent également fonctionner pour vous. Non seulement cela rend la recherche des informations dont vous avez réellement besoin plus rapide et plus facile, mais cela signifie également que l'entretien des connaissances est de loin plus simple. En savoir plus sur les avantages d'adopter un système de gestion des connaissances à l'échelle de l'entreprise.
En mettant en œuvre une approche de base de connaissances courte, vous passez à autre chose que de devoir constamment télécharger entièrement une nouvelle documentation. Une mise à jour d'une phrase dans un document de 20 pages signifie que vous devez re-télécharger ce document entier et vous assurer que tout le monde est au courant du changement, puisqu'il est enfoui dans le neuvième point de la page 12.
Alternativement, une mise à jour d'une phrase dans un morceau de connaissance de quatre phrases peut se faire en quelques secondes. Cette approche rend également beaucoup plus facile de vérifier les informations de petite taille pour garantir leur précision que de vérifier des documents plus longs, chaque morceau de connaissance pouvant être vérifié individuellement comme correct — et la vérification est finalement le cœur de la création d'un réseau de connaissances en lequel tout le monde peut avoir confiance.
Bien sûr, nous savons qu'ironiquement, ce sont beaucoup de mots pour expliquer pourquoi un contenu court est une meilleure approche pour l'architecture des connaissances, alors voici le tl;dr : le contenu de petite taille est plus facile à ajouter, plus facile à mettre à jour, plus facile à vérifier et plus facile à rechercher. Pensez-y comme des cartes de vocabulaire versus le dictionnaire : l'une a tout mais ne vous aidera pas à vous préparer pour le quiz de la semaine prochaine, tandis que l'autre est exactement ce dont vous avez besoin pour passer le quiz, peut être augmentée pour vous aider à passer le partiel et l'examen final, et est suffisamment flexible pour être réorganisée de mille manières différentes. Lequel choisiriez-vous ?
Lorsque Google a introduit son Knowledge Graph sur les pages de résultats des moteurs de recherche (SERPs) en 2012, ses extraits mis en avant (ces courts points de données pertinents qui vivent en haut de la page) sont devenus la référence pour ceux qui avaient besoin d'une réponse rapide. Énormément dépendant du scraping de données provenant de sites comme Wikipedia, Google a pu tirer parti des données compilées par d'autres pour vous garder dans son écosystème — un avantage pour un modèle de revenus basé sur la publicité. Mais autre chose est aussi arrivée : le trafic vers Wikipedia a diminué. Bien qu'un statisticien ait le droit de nous rappeler que la corrélation n'implique pas la causalité, nous pouvons également observer notre propre comportement pour avoir une idée de ce qui s'est passé. Si tout ce que vous devez savoir est, disons, qui a gagné le Prix Nobel de Physique cette année et que la réponse se trouve en haut de la page, il n'est pas nécessaire de continuer à chercher parmi les autres 105 millions de résultats.
Nous le savons instinctivement, mais en ce qui concerne nos portails de connaissances, nous avons souvent tendance à les configurer pour qu'ils agissent comme des dépôts, et non comme un moyen de faire émerger facilement les informations dont nous avons besoin. C'est pourquoi — et cela peut être difficile à entendre — nous devons complètement repenser notre approche.
Si votre portail de connaissances d'entreprise est comme la plupart, lorsque vous avez une question, vous devez savoir a) exactement ce que vous cherchez ou b) vous devez parcourir des centaines (ou des milliers !) de mots dans des FAQ multi-pages ou des PDF pour trouver une réponse qui est enfouie quelque part.
Control-F a été essentiel pour faire fonctionner cette configuration, mais pourquoi devriez-vous utiliser ce qui est en fin de compte un contournement juste pour obtenir une réponse simple ? Non seulement cela impose le fardeau à l'employé de déterrer les connaissances (ce qui peut prendre beaucoup de temps), mais cela signifie que chaque fois que l'une de ces connaissances change, l'entreprise doit télécharger un tout nouveau PDF, vidéo ou FAQ. Cela fait perdre du temps — et des budgets.
La meilleure solution consiste à repenser entièrement votre architecture de connaissances et à se tourner vers des morceaux de connaissances courts, faciles à consommer (et à mettre à jour), discrets.
Recherche et sauvetage
« Regarde, ce n'est pas si mauvais », vous dites probablement en ce moment, « ça fait le travail ! » Alors parlons de cela. Ce n'est même pas la première fois que nous avons parlé de cela sur le blog de Guru. Il y a presque trois ans, nous avons souligné que :
Les commerciaux passent jusqu'à un tiers de leur journée à chercher des informations nécessaires pour faire leur travail. Les informations sont nécessaires à la demande, et les solutions actuelles ne sont pas adaptées à un monde à la demande. Les docs et wikis vous obligent à utiliser Control+F pour trouver des mots, puis vous laissent reconstituer les réponses.
Si vous discutez avec un client et devez répondre à une question, vous n'avez pas le temps de passer par le long et inefficace processus actuel pour trouver la réponse. Rechercher le document qui aura la bonne réponse, ouvrir ce document, chercher un mot-clé, et après tout ça au lieu que votre réponse apparaisse, vous voyez que le mot que vous avez tapé apparaît quinze fois. Pour obtenir l'information appropriée, vous devez parcourir toutes les options, pendant ce temps votre client attend sa réponse.
Mais cela va au-delà de la simple perte de précieuses secondes. Du contenu plus long est tout simplement plus difficile à rechercher que du contenu plus court. Sortons cela du domaine de la gestion des connaissances et mettons-le dans un domaine qui nous concerne tous : comment nous engageons avec le contenu à des fins de loisirs.
Voici une question à laquelle vous ne savez peut-être pas répondre : Quelle année Les Simpsons a-t-il été diffusé pour la première fois ? Vous consultez Wikipedia, entrez « Les Simpsons » et obtenez cette page avec plus de 17 000 mots. Vous comptez sur votre fidèle Control-F et recherchez « première » et voilà ce qui arrive :
Attendez, quoi? Il s'avère que vous deviez rechercher « sortie » :
Non seulement vous deviez savoir exactement comment cette page (hautement organisée, devons-nous le souligner) est configurée, mais vous deviez également connaître exactement la terminologie utilisée par les rédacteurs pour indiquer une date de début. Pendant ce temps, si vous allez sur Google et tapez simplement « première des Simpsons », vous obtenez ceci :
Recherchez « sortie des Simpsons » et vous obtenez les mêmes informations, même si elles sont présentées un peu différemment :
De toute façon, le résultat est utile, rapide et, surtout, facile à trouver indépendamment du mot exact que vous avez utilisé. Vous n'avez même pas eu besoin d'utiliser Control-F.
Je n'ai même pas trouvé ce que je cherche
Maintenant, revenons à cette discussion sur la gestion des connaissances. Vos PDF serrés, en police de 10pt, de trois pages et vos FAQ de 48 articles sont super — pour économiser sur les coûts d'impression. Ils ne sont pas idéaux pour se concentrer facilement sur ce que vos employés doivent savoir, que ce soit des informations sur les avantages lors de l'intégration, de la documentation produit lors d'un lancement, ou même essayer de trouver le bon document à distribuer.
C'est drôle, plus nous avons numérisé nos connaissances, plus nous avons dû compter sur des solutions de contournement pour arriver à ce que nous devions trouver. Ces manuels tant détestés de votre jeunesse ? L'index était la partie avec laquelle vous avez passé le plus de temps de qualité. Après tout, il vous indiquait exactement où trouver ce dont vous aviez besoin — et ce qu'il fallait ignorer — et comprenait généralement aussi des explications contextuelles (ex : le débarquement sur la Lune, la réaction de l'URSS).
Maintenant ? Nous nous forcions à faire un travail que les ordinateurs et l'IA peuvent faire plus efficacement, si nous les laissons faire. Stocker votre connaissance en morceaux de petite taille signifie que toute recherche contextuelle peut se faire beaucoup plus rapidement. Beaucoup d'entreprises parlent de leurs capacités d'apprentissage automatique et d'IA dans la recherche d'entreprise — mais toutes ces solutions sont inutiles si tout ce qu'elles peuvent faire est de fournir un document de 30 pages que vos employés doivent continuer à chercher.
Si les documents ne sont pas destinés à être imprimés, il n'y a aucune raison de ne pas les diviser en composants individuels pour améliorer l'expérience de référence des connaissances. Sinon, en tant qu'entreprise, vous pourriez payer vos employés pour effectuer le travail manuel de recherche à travers 50 instances surlignées du mot "sécurité" dans un document produit — et ils pourraient encore ne pas trouver ce qu'ils cherchent, car ils ne peuvent pas ajouter plus de contexte à une recherche Control-F.
Cette approche ne bénéficie pas seulement à ceux qui ajoutent et maintiennent les connaissances ; c'est également un énorme coup de pouce pour votre équipe de revenus. Lorsqu'un commercial essaie de conclure un accord, préférez-vous qu'elle ait un accès instantané à des informations spécifiques ou... qu'elle exécute une commande de recherche sur un document de préparation à la vente de 45 points ? Si votre agent de support client est à l'autre bout d'un appel téléphonique en colère, voulez-vous qu'il feuillette furieusement une FAQ pour trouver une réponse, ou l'habiliter à extraire juste la section pertinente ?
Construire une fondation de connaissances durable
Nous avons vu que les cartes de connaissances de petite taille fonctionnent pour nous, c'est pourquoi nous savons qu'elles peuvent également fonctionner pour vous. Non seulement cela rend la recherche des informations dont vous avez réellement besoin plus rapide et plus facile, mais cela signifie également que l'entretien des connaissances est de loin plus simple. En savoir plus sur les avantages d'adopter un système de gestion des connaissances à l'échelle de l'entreprise.
En mettant en œuvre une approche de base de connaissances courte, vous passez à autre chose que de devoir constamment télécharger entièrement une nouvelle documentation. Une mise à jour d'une phrase dans un document de 20 pages signifie que vous devez re-télécharger ce document entier et vous assurer que tout le monde est au courant du changement, puisqu'il est enfoui dans le neuvième point de la page 12.
Alternativement, une mise à jour d'une phrase dans un morceau de connaissance de quatre phrases peut se faire en quelques secondes. Cette approche rend également beaucoup plus facile de vérifier les informations de petite taille pour garantir leur précision que de vérifier des documents plus longs, chaque morceau de connaissance pouvant être vérifié individuellement comme correct — et la vérification est finalement le cœur de la création d'un réseau de connaissances en lequel tout le monde peut avoir confiance.
Bien sûr, nous savons qu'ironiquement, ce sont beaucoup de mots pour expliquer pourquoi un contenu court est une meilleure approche pour l'architecture des connaissances, alors voici le tl;dr : le contenu de petite taille est plus facile à ajouter, plus facile à mettre à jour, plus facile à vérifier et plus facile à rechercher. Pensez-y comme des cartes de vocabulaire versus le dictionnaire : l'une a tout mais ne vous aidera pas à vous préparer pour le quiz de la semaine prochaine, tandis que l'autre est exactement ce dont vous avez besoin pour passer le quiz, peut être augmentée pour vous aider à passer le partiel et l'examen final, et est suffisamment flexible pour être réorganisée de mille manières différentes. Lequel choisiriez-vous ?
Vous voulez apprendre comment Guru peut fonctionner pour vous et votre équipe ?