Rethinking Your Knowledge Base Architecture: Why Bite-Size is Best
If you're relying on Control-F to search through multi-page documents in your corporate knowledge repository, it's time to rethink your knowledge architecture entirely — and move towards short-form, easily consumable, discrete pieces of knowledge.
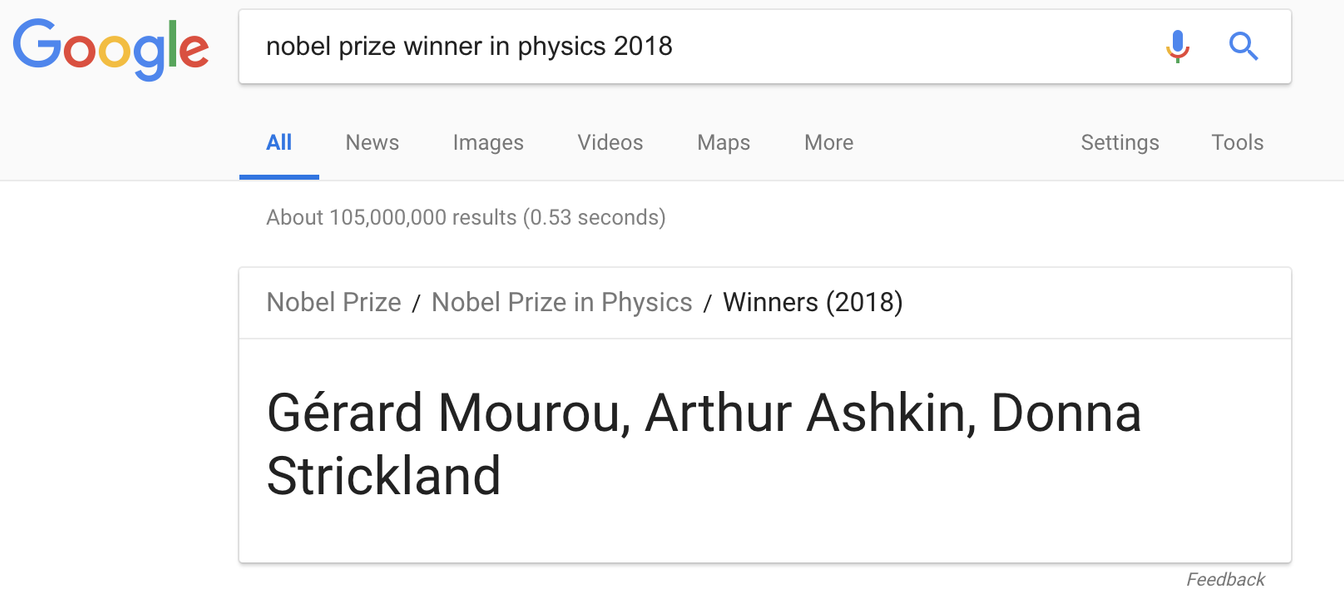
When Google introduced its Knowledge Graph on search engine results pages (SERPs) in 2012, its featured snippets (those short, relevant data points that live at the top of the page) became the go-to for those needing a quick answer. Heavily reliant on scraping data from sites like Wikipedia, Google was able to leverage data compiled by others to keep you in their ecosystem — a boon for an advertising-driven revenue stream. But something else also happened: traffic to Wikipedia dropped. While any statistician would be within her rights to remind us that correlation does not equal or imply causation, we can also look at our own behavior to get a sense of what happened. If all you need to know is, say, who won the Nobel Prize in Physics this year and the answer is at the top of the page, there’s no need to keep searching through the other 105 million results.
We know this instinctively, but when it comes to our knowledge portals, we’re often setting them up to act as repositories, not as a way to easily surface information we need. That’s why — and this may be hard to hear — we need to completely rethink our entire approach.
If your corporate knowledge portal is like most, when you have a question, you have to know a) exactly what you’re looking for or b) you have to search through hundreds (or thousands!) of words in multi-page FAQs or PDFs to find an answer that is buried somewhere in them.
Control-F has been integral to making this setup work, but why should you have to use what’s effectively a workaround just to get a simple answer? Not only does it put the burden on the employee to dig up knowledge (which can take a not insignificant amount of time), it means that any time any of that knowledge changes, the company has to upload an entirely new PDF, video, or FAQ. That wastes time — and budgets.
The better solution is to rethink your knowledge architecture entirely and move towards short-form, easily consumable (and updatable), discrete pieces of knowledge.
Search and rescue
“Look, it’s not that bad,” you’re probably saying right now, “it gets the job done!” So let’s talk about that. This isn’t even the first time we’ve talked about this on the Guru blog. Almost three years ago, we pointed out that:
Salespeople spend up to one third of their days looking for information needed to do their jobs. Information is needed on demand, and the current solutions aren’t built for an on demand world. Docs and wikis force you to use Control+F to find words and then leave you to piece together the answers.
If you're chatting with a customer and need to answer a question, you don't have time to go through the current long and inefficient process to find the answer. Searching for the doc that will have the right answer, opening that doc, searching for a keyword, and after all that instead of your answer appearing, you see that the word that you typed appears fifteen times. To get the proper information you have to click through all of the options, meanwhile your customer is waiting for their answer.
But it goes beyond just wasting valuable seconds. Longer content is just more difficult to search than shorter content. Let’s take this out of the sphere of knowledge management, and into one we can all relate to: how we engage with content for leisure purposes.
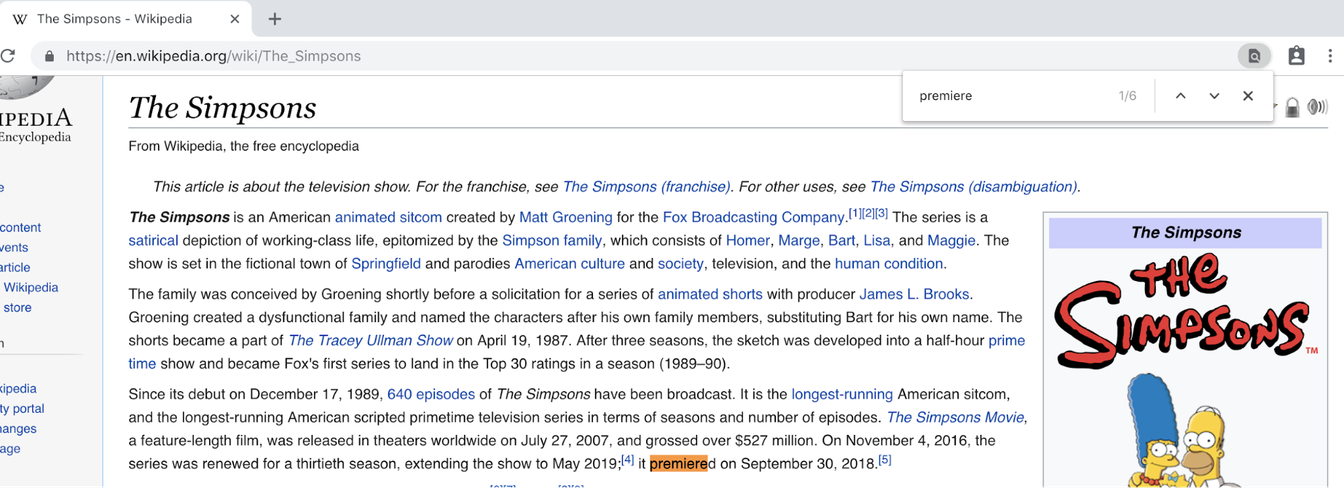
Here’s a question you may or may not know the answer to: What year did The Simpsons premiere? You pull up Wikipedia, put in “The Simpsons” and get this page with over 17,000 words. You rely on your old standby Control-F and search “premiere” and this happens:
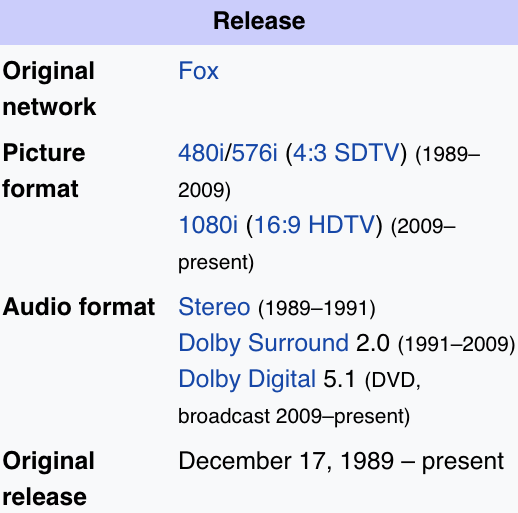
Wait, what? Turns out you needed to search for “release”:
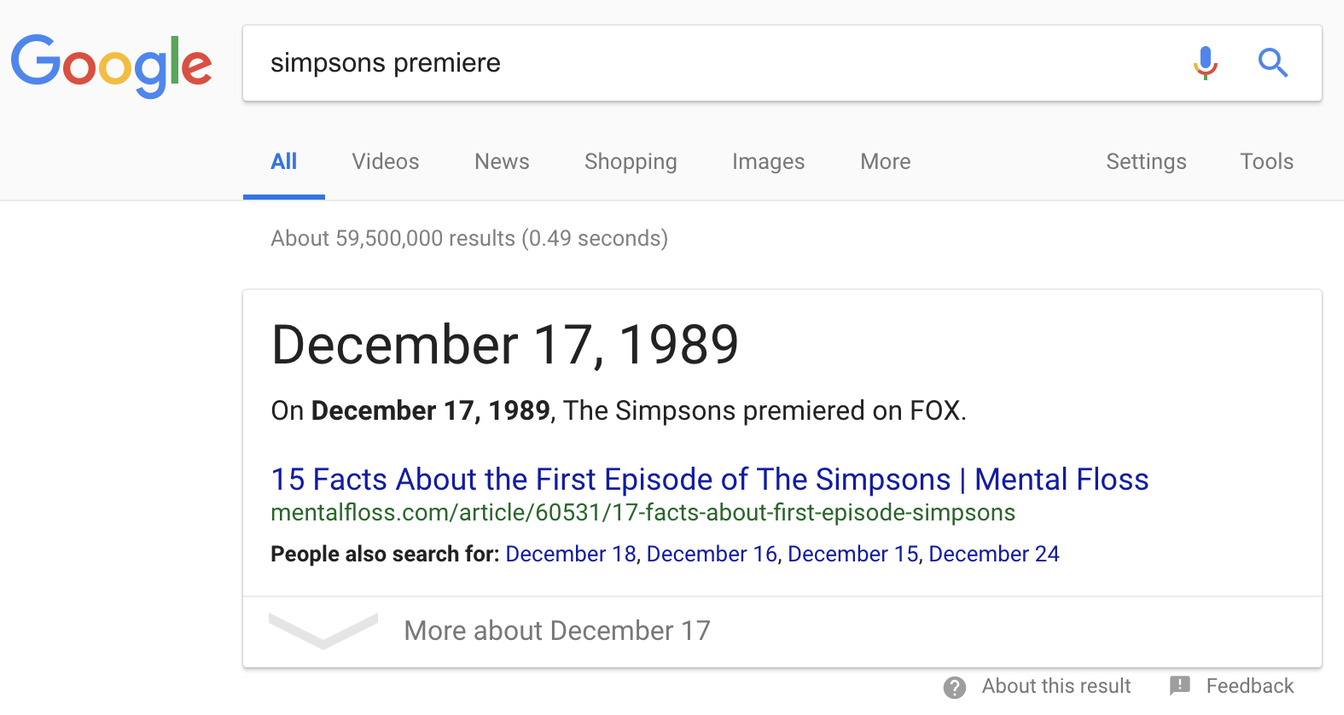
Not only did you need to know exactly how this (highly organized, we should point out) page is set up, you need to know exactly the terminology the writers have used to indicate a start date. Meanwhile, if you go to Google and just type in “Simpsons premiere” you get this:
Search for “Simpsons release” and you get the same information, albeit presented a bit differently:
Either way, the result is helpful, fast, and, most importantly, easy to find regardless of the exact wording you’ve used. You didn’t even have to use Control-F.
I still haven’t found what I’m looking for
Now, let’s move this discussion back towards knowledge management. Your tightly spaced, 10pt font, three-page PDFs and 48-item FAQs are great — for saving on printing costs. They’re not great for easily focusing on exactly what your employees need to know, whether we’re talking about benefits information at onboarding, product documentation at a launch, or even trying to find the right one-sheet to distribute.
Funnily enough, the more of our knowledge we’ve digitized, the more we’ve had to rely on workarounds to actually zero-in on what we’ve had to find. Those much-loathed textbooks of your youth? The index was the part with which you spent the most quality time. After all, it told you exactly where to find what you needed — and to ignore what you didn’t — and usually included contextual breakdowns as well (ex: The Moon Landing, USSR’s reaction to).
Now? We’re making ourselves do work that computers and AI can do more efficiently, if we just let them. Storing your knowledge in bite-size chunks means that any contextual searching can happen much, much more quickly. A lot of companies talk about their machine learning and AI capabilities in enterprise search — but all of those solutions are useless if all that they can do is bring up a 30-page document that your employees still have to search through.
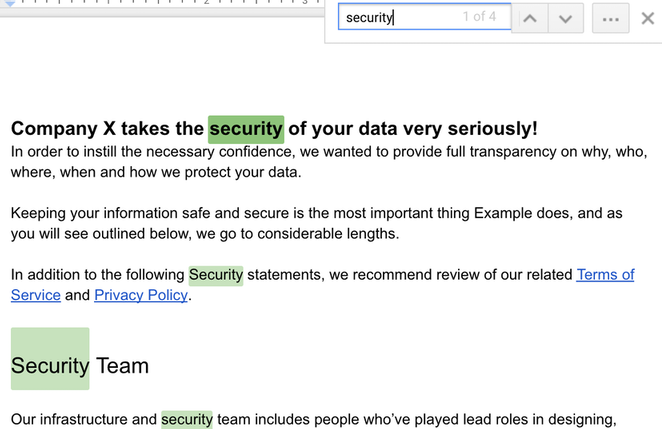
If documents aren’t intended to be printed, there’s no reason not to break them up into individual components to make for a better knowledge reference experience. Otherwise, as a company, you may be paying your employees to do the manual work of searching through 50 highlighted instances of the word “security” in a product document — and they still might not find what they’re looking for, because they can’t put more context into a Control-F search.
This approach doesn’t just benefit those adding and maintaining knowledge; it’s a huge help to your revenue team as well. When a salesperson is trying to close a deal, would you rather she have instant access to specific information or... run a Find command on a 45-bullet sales readiness document? If your customer support rep is on the receiving end of an angry phone call, do you want him furiously scanning through a FAQ for an answer, or empower him to pull up just the relevant section?
Building a sustainable knowledge foundation
We’ve seen bite-size knowledge cards work for us, which is why we know that they can work for you, too. Not only does it make finding the information you really need faster and easier, it also means that knowledge maintenance is far simpler. Learn more about the benefits of adopting a company-wide knowledge management system.
By implementing a short-form approach to knowledge base architecture, you get away from constantly having to upload entirely new documentation. A one-sentence update in a 20-page document means that you have to re-upload that entire document and make sure everyone is aware of the change, as it’s buried in the ninth bullet point on page 12.
Alternatively, a one-sentence update in a four-sentence piece of knowledge can happen in matter of seconds. This approach also makes it much easier to verify bite-size information to ensure its accuracy than it is to verify longer documents, as each piece of knowledge can be individually verified as correct — and verification is ultimately the core of creating a knowledge network everyone can trust.
Sure, we know that, ironically, this is a lot of words to explain why short content is a better approach to knowledge architecture, so here’s the tl;dr: bite-size content is easier to add, easier to update, easier to verify, and easier to search. Think of it as vocabulary flash cards vs. the dictionary: one has everything but won’t help you prepare for next week’s quiz, while the other is just what you need to get through the quiz, can be augmented to get you through the midterm and the final, and is flexible enough to reorganized in a million different ways. Which would you pick?
When Google introduced its Knowledge Graph on search engine results pages (SERPs) in 2012, its featured snippets (those short, relevant data points that live at the top of the page) became the go-to for those needing a quick answer. Heavily reliant on scraping data from sites like Wikipedia, Google was able to leverage data compiled by others to keep you in their ecosystem — a boon for an advertising-driven revenue stream. But something else also happened: traffic to Wikipedia dropped. While any statistician would be within her rights to remind us that correlation does not equal or imply causation, we can also look at our own behavior to get a sense of what happened. If all you need to know is, say, who won the Nobel Prize in Physics this year and the answer is at the top of the page, there’s no need to keep searching through the other 105 million results.
We know this instinctively, but when it comes to our knowledge portals, we’re often setting them up to act as repositories, not as a way to easily surface information we need. That’s why — and this may be hard to hear — we need to completely rethink our entire approach.
If your corporate knowledge portal is like most, when you have a question, you have to know a) exactly what you’re looking for or b) you have to search through hundreds (or thousands!) of words in multi-page FAQs or PDFs to find an answer that is buried somewhere in them.
Control-F has been integral to making this setup work, but why should you have to use what’s effectively a workaround just to get a simple answer? Not only does it put the burden on the employee to dig up knowledge (which can take a not insignificant amount of time), it means that any time any of that knowledge changes, the company has to upload an entirely new PDF, video, or FAQ. That wastes time — and budgets.
The better solution is to rethink your knowledge architecture entirely and move towards short-form, easily consumable (and updatable), discrete pieces of knowledge.
Search and rescue
“Look, it’s not that bad,” you’re probably saying right now, “it gets the job done!” So let’s talk about that. This isn’t even the first time we’ve talked about this on the Guru blog. Almost three years ago, we pointed out that:
Salespeople spend up to one third of their days looking for information needed to do their jobs. Information is needed on demand, and the current solutions aren’t built for an on demand world. Docs and wikis force you to use Control+F to find words and then leave you to piece together the answers.
If you're chatting with a customer and need to answer a question, you don't have time to go through the current long and inefficient process to find the answer. Searching for the doc that will have the right answer, opening that doc, searching for a keyword, and after all that instead of your answer appearing, you see that the word that you typed appears fifteen times. To get the proper information you have to click through all of the options, meanwhile your customer is waiting for their answer.
But it goes beyond just wasting valuable seconds. Longer content is just more difficult to search than shorter content. Let’s take this out of the sphere of knowledge management, and into one we can all relate to: how we engage with content for leisure purposes.
Here’s a question you may or may not know the answer to: What year did The Simpsons premiere? You pull up Wikipedia, put in “The Simpsons” and get this page with over 17,000 words. You rely on your old standby Control-F and search “premiere” and this happens:
Wait, what? Turns out you needed to search for “release”:
Not only did you need to know exactly how this (highly organized, we should point out) page is set up, you need to know exactly the terminology the writers have used to indicate a start date. Meanwhile, if you go to Google and just type in “Simpsons premiere” you get this:
Search for “Simpsons release” and you get the same information, albeit presented a bit differently:
Either way, the result is helpful, fast, and, most importantly, easy to find regardless of the exact wording you’ve used. You didn’t even have to use Control-F.
I still haven’t found what I’m looking for
Now, let’s move this discussion back towards knowledge management. Your tightly spaced, 10pt font, three-page PDFs and 48-item FAQs are great — for saving on printing costs. They’re not great for easily focusing on exactly what your employees need to know, whether we’re talking about benefits information at onboarding, product documentation at a launch, or even trying to find the right one-sheet to distribute.
Funnily enough, the more of our knowledge we’ve digitized, the more we’ve had to rely on workarounds to actually zero-in on what we’ve had to find. Those much-loathed textbooks of your youth? The index was the part with which you spent the most quality time. After all, it told you exactly where to find what you needed — and to ignore what you didn’t — and usually included contextual breakdowns as well (ex: The Moon Landing, USSR’s reaction to).
Now? We’re making ourselves do work that computers and AI can do more efficiently, if we just let them. Storing your knowledge in bite-size chunks means that any contextual searching can happen much, much more quickly. A lot of companies talk about their machine learning and AI capabilities in enterprise search — but all of those solutions are useless if all that they can do is bring up a 30-page document that your employees still have to search through.
If documents aren’t intended to be printed, there’s no reason not to break them up into individual components to make for a better knowledge reference experience. Otherwise, as a company, you may be paying your employees to do the manual work of searching through 50 highlighted instances of the word “security” in a product document — and they still might not find what they’re looking for, because they can’t put more context into a Control-F search.
This approach doesn’t just benefit those adding and maintaining knowledge; it’s a huge help to your revenue team as well. When a salesperson is trying to close a deal, would you rather she have instant access to specific information or... run a Find command on a 45-bullet sales readiness document? If your customer support rep is on the receiving end of an angry phone call, do you want him furiously scanning through a FAQ for an answer, or empower him to pull up just the relevant section?
Building a sustainable knowledge foundation
We’ve seen bite-size knowledge cards work for us, which is why we know that they can work for you, too. Not only does it make finding the information you really need faster and easier, it also means that knowledge maintenance is far simpler. Learn more about the benefits of adopting a company-wide knowledge management system.
By implementing a short-form approach to knowledge base architecture, you get away from constantly having to upload entirely new documentation. A one-sentence update in a 20-page document means that you have to re-upload that entire document and make sure everyone is aware of the change, as it’s buried in the ninth bullet point on page 12.
Alternatively, a one-sentence update in a four-sentence piece of knowledge can happen in matter of seconds. This approach also makes it much easier to verify bite-size information to ensure its accuracy than it is to verify longer documents, as each piece of knowledge can be individually verified as correct — and verification is ultimately the core of creating a knowledge network everyone can trust.
Sure, we know that, ironically, this is a lot of words to explain why short content is a better approach to knowledge architecture, so here’s the tl;dr: bite-size content is easier to add, easier to update, easier to verify, and easier to search. Think of it as vocabulary flash cards vs. the dictionary: one has everything but won’t help you prepare for next week’s quiz, while the other is just what you need to get through the quiz, can be augmented to get you through the midterm and the final, and is flexible enough to reorganized in a million different ways. Which would you pick?
Want to learn how Guru can work for you and your team?